VapUFS Implementation Hell: Week 2 of VoreStation Development
2023-08-13
written by Niko Chow-Stuart (Lead Developer)

while unfortunately, as i expected, i wasn't able to do as much work on the filesystem the week before last;
after managing to get somewhat back on track this week, i've finished nearly all aspects of VapUFS's
implementation!
regarding the work i've done, i should probably go more in-depth about this image that i posted on my
personal social media accounts a bit ago.
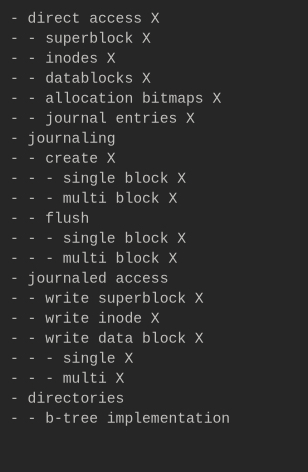
starting at the section labeled "direct access", the implementation was started by writing some basic
functions for retrieving the core structures of the filesystem off of the disk (using a generic abstraction
layer for the disk, not with any actual disk drivers). this was an important step to take, as very early on,
i decided to make it as clear as possible that all structs would be stored on-disk in big-endian values.
because of this, i was able to add in a step in the retrieval process that (depending on architecture)
converts the big-endian values to the cpu's native byte-ordering, and back again when storing.
as the filesystem is journaled, i then began the work of implementing the creation of journal entries as
well as the somewhat more complex step of "flushing" the journal entries (i.e. performing them if they are
not corrupt, and then marking them as complete). this section of implementation took much longer than the
previous (which i'd say maybe took like an hour at most, including the time i spent procrastinating).
the source code (which i'll get to later in this post!) of the filesystem goes much more in-depth about
how everything works.
regarding journaling, there is one major aspect listed in the image, that being the classification of
single block writes and multi block writes. one thing that i believe i have yet to clarify in the source
code is that the defined disk block size for the filesystem should be at least large enough to be
able to store the largest struct for the file system (which i believe is the superblock, spanning around
156 bytes). this means that all metadata writes (which are journaled) can be performed using a single block.
i was originally planning on using this strategy for all writes, where they would be broken up into single
block writes in the journal; however, there is one area where this would be a bad idea: directories.
directories, in the typical UFS fashion, are stored in an inode's data blocks; however, they could
theoretically span multiple blocks in length. because of this, as well as the fact that they would be stored
in a potentially fragile b-tree structure, i decided to add a multi block journaled write. this way, if the
system is shut down during a directory contents update (e.g. new folder or file), the directory shouldn't
become corrupted.
another potential confusion in the original image would be the difference between "journaling" and
"journaled access" (which i admit is probably not the best way to label it). "journaling" here refers to
directly creating and executing journal entries, whereas "journaled access" refers to higher-level
functions that manage creating journaled writes for various metadata structs as well as file data. notably,
file data journaled writes will automatically decide between single block and multi block operations
depending on the amount of data being written. this section of implementation also took quite a bit, as it
required extra thought into the planning of journal executions and failure states (one of which i realised
while writing this that i forgot to implement, that being the deallocation of data blocks upon source block
corruption).
other than that, hopefully the only thing left is to write a serialisable b-tree implementation for
directory contents. i'm planning on also storing a pure array of file and directory names along-side the
b-tree in order to assist with recovery upon corruption, however none of that is written yet so i'll see
how things go when the time comes!
regarding the release of the VapUFS source code, it should be up by the time this goes public! and by that
i mean, you can view it here:
link to git repo.
if anyone has trouble viewing it, just shoot me an email at
nikocs@voremicrocomputers.com and i'll try to fix it
asap!
that's it for the progress this week! hopefully i'll actually start releasing these weekly now that i have
a bit more time on my hands.
i will note that donations to our LiberaPay are very much appreciated, especially as i'm currently bouncing
between this and some other stuff to try to pay for everything! :D

other than that, have a good week and happy voring!
 image made by @cathodegaytube!
image made by @cathodegaytube!